Introduction
This document describes the design and features of a standard single tier messaging solution relying on the Axigen Mail Server software, the storage subsystem and the Cluster Management software. The base architecture has been tailored having in mind the need for the fault-tolerance of the systems and services part of the resulting environment. The global architecture for the solution is described along with process and information flow explanations.
Solution Functionality
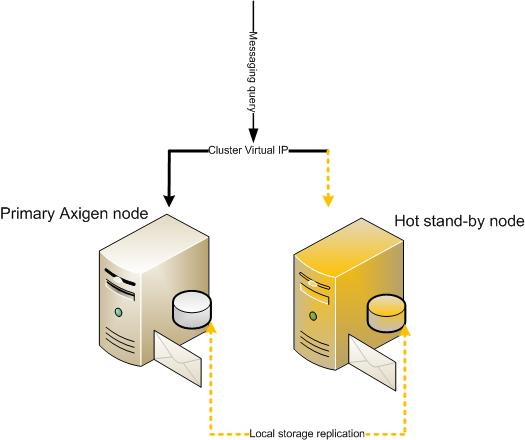
For the setup described in this document all services are stateful, thus all requests to an account are sent to a single machine. If that machine experiences a fault and can no longer respond to requests, a mechanism is required to ensure that, in the event of a failure on one machine, the other node takes over the task of servicing requests for that account, thus providing high-availability.
The cluster management software provides this exact functionality; it ensures that, if one node fails, the backup node will automatically detect the fault and start the required service in place of the failed node, providing minimal downtime to that service. This detection process is achieved through the heartbeat mechanism deployed along with the clustering software.
This approach to high availability focuses on a two node cluster architecture in an active/passive configuration where a designated stand-by host will be available to relocate our resources in case of a failure encountered in the primary system. For such a setup, single points of failure are eliminated via redundant components such as multiple communication paths between nodes, independent power supplies for the two hosts, redundant fans, RAID storage configurations etc.
Storage
While migrating the running services from one failed node to another healthy node, the storage information between the two nodes must be the same. This can be achieved by using a block level replication software and local disks that reside on each node. Of course, having physical external disk array storage (SAN, JBOD, etc) connected to both nodes is also supported and eliminates the software replication from the solution architecture.
The first, software replication of local disks, method is explained further in this document.
Fencing
The cluster management application is the one that acts as the manager of the entire deployment and makes sure the right decisions are taken (based on the configured options) in order to ensure service availability and continuity. The high-availability mechanism relies heavily on the data replication process between the storage devices of the two nodes part of the cluster. This replication process can be interrupted only by the cluster management software through a hardware controlled method of disabling nodes by the request and execution of a hard reset (power cycle) by a power switch device. This device is also called a fencing device because it prevents the abnormal operation of a node interfere with cluster data integrity. By physically resetting a node, the data replication process is disabled and any storage corruption is avoided.
Usually, power cycling fencing can be performed either with management enabled power switches – which can physically reset the malfunctioning node – or via management interfaces (like iDRAC interfaces from Dell, for example), through the IPMI protocol.
Solution Architecture Diagram
Hardware Requirements
The hardware recommendation for all of the solution nodes should match the performance of the following system configuration. More powerful hardware configurations can also be used and the hardware configuration should be accepted as a baseline example:
-
CPU: Intel Xeon Quad-Core (>2 GHz, 1333 MHz FSB)
-
RAM: 8 GB Fully Buffered
-
Array Controller (RAID 0/1/1+0/5)
-
15,000 RPM SAS Hot Plug Hard Drives
-
2x Gigabit Network Adapters
As an alternative to the configuration example above, any compatible hardware parts and systems from any different vendor may be used.
Only heavy duty and reliable equipment (server framework / rackable) must be deployed within the clustering environment.
Also, a fencing device is required for the whole setup, a commonly used one is the power switch.
Software Requirements
Cluster Management
Axigen has been tested and is officially supported in a clustered single-tier solution with the following Cluster Management software:
-
Linux Cluster (Pacemaker and Corosync)
-
Windows Failover Cluster
Linux Cluster
The Linux Cluster project provides a high-availability solution which promotes reliability, availability, and serviceability. The project's main software product is Pacemaker, an open source high availability resource manager that is working usually with Corosync, an open source cluster engine.
Storage Replication
While there may be many software with this functionality, the DRBD replication software suite is one that has been tested and provides full block-level replication functionality over the network of one or more disk partitions.